Authorization in MCP Servers: What’s Missing and What’s Coming

The 2025-03-26 revision to Model Context Protocol and its addition of OAuth 2.1 is promising. But more work is needed to make the state of authorization to MCP servers in AI clients consistent with the standard OAuth flows we’ve been using in conventional SaaS applications for over a decade. MCP server implementations need to evolve significantly to get beyond local credential storage and support secure enterprise-ready deployment.
Before the MCP 2025-03-26 revision
Most MCP server and client implementations available today were built before the spec was revised a few weeks ago. This current phase has mostly comprised of local servers communicating over STDIO.
A common pattern for many current MCP servers out there in the wild, say, one that connects to Gmail or some other service behind OAuth, is to instruct users to create an OAuth client with the provider (e.g. Google), open a URL in the browser, and complete a PKCE flow which calls back to the MCP server which then stores the credentials somewhere in the filesystem (example).
There’s a number of obvious limitations and risks here, namely the storage of plaintext refresh tokens in random filesystem locations, and software supply chain risks due to people running random MCP servers.
Given the proliferation of these local servers, the updated MCP spec couldn’t come soon enough. People have likened the environment to the ActiveX of the AI era.

In all fairness, the entire MCP specification is very new, with the original version only announced in November 2024. The spec was introduced with support for HTTP transport but included no guidelines on authentication or authorization – not even support for authorization headers. Considering these limitations, little has been possible in terms of authentication or the possibility of remotely hosting MCP servers until now.
The breakneck speed of this space is why we are here, and it’s great that people have had the opportunity to experiment with MCP before it’s ready for go-time. However, the thousands of MCP server repos already published need significant work to become suitable for use in remote MCP contexts and eventually fit into enterprise permission models.
What’s changed in the MCP spec
The second and latest version of the MCP spec proposes a comprehensive authorization framework for MCP servers utilizing HTTP transport and OAuth 2.1. This includes a flow for user auth as well as third party authorization. These are the MCP authentication flows we’ve been waiting for, but clients and servers are still working on catching up.
User auth flow
To support user auth, given a request, the MCP server may now respond with a 401 Unauthorized and the client (e.g. Claude Desktop, ChatGPT, or LMStudio) can take the user through an authorization code grant flow in order to determine their identity and allow the client to take actions on their behalf. The spec indicates that utilizing the authorization code grant flow with PKCE is “strongly recommended” since MCP clients should be treated as public clients. The MCP server returns an access and refresh token to the client and expects a valid access token to be provided in subsequent requests. The client is also responsible for refreshing expired tokens.

Third-party authorization flow
I had been musing on how the current state of permissioning for MCP servers could be improved by allowing the MCP server to tell clients to redirect to a third party authorization URL and go through a PKCE flow with the relevant OAuth server. I happily realized this has already been proposed in the latest spec. This is the aptly named “third-party authorization flow” whereby an MCP server can do exactly this.

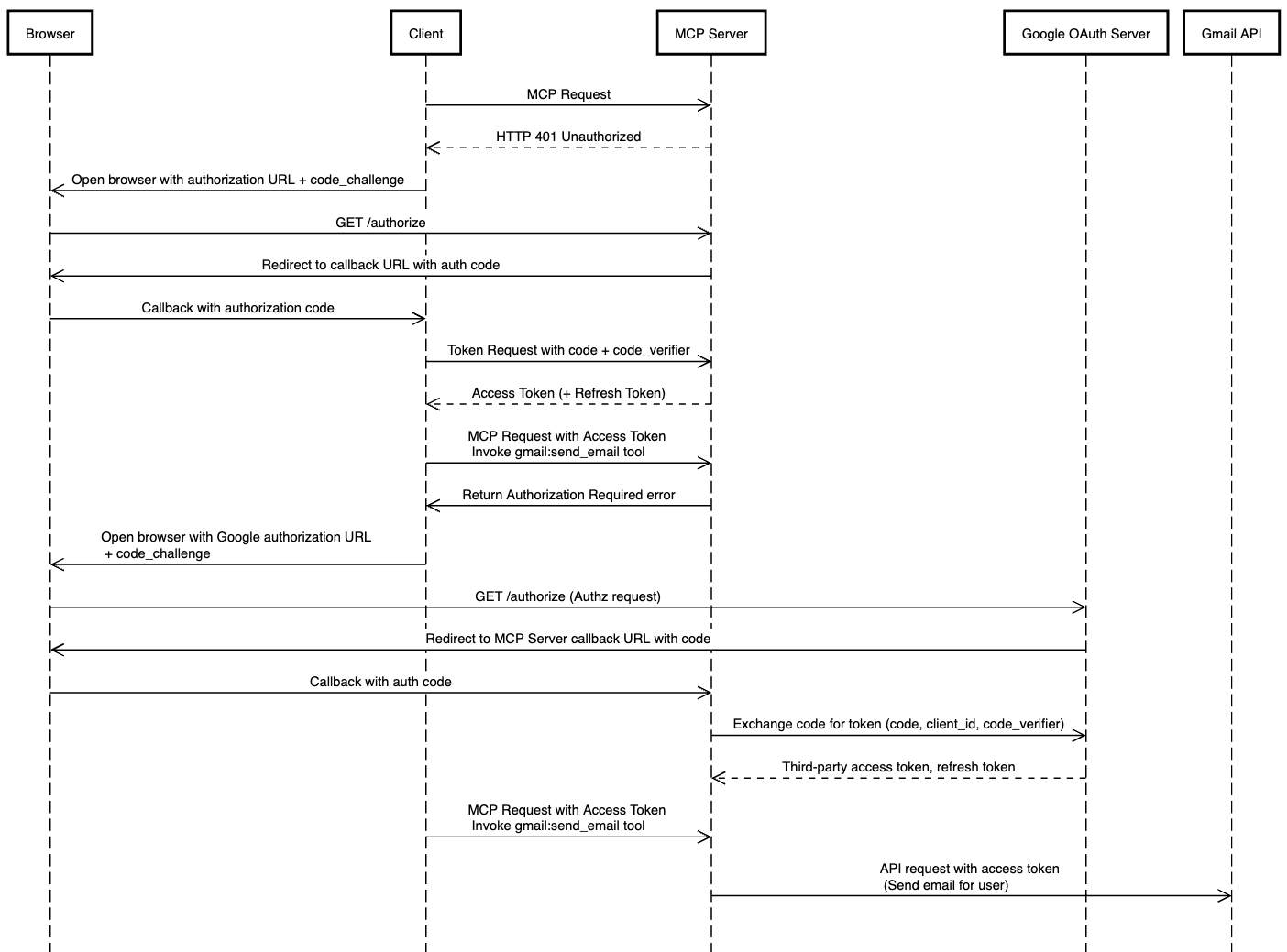
What MCP auth looks like in a spec-compliant implementation
What should all of this look like? Imagine a user who:
Wants to send an email via Gmail from their AI client (e.g. Claude Desktop).
The user’s Google account is managed by a Google Workspace
The MCP Server requires authentication separate from Google, via Okta over OIDC
An ideal flow might look like this:
User prompts an AI client to send a Gmail message
The AI client recognizes that a tool is available in a known MCP server for this, and attempts to invoke the tool after checking with the user for confirmation.
The MCP server responds with a 401 Unauthorized and a browser window is opened where the user is brought to Okta to authenticate.
After successfully authenticating, the user is able to access the MCP server via their client.
The MCP server determines that it does not have stored Google OAuth credentials for the user
The MCP server responds and requests that the client direct the user to authorize with Google
The user successfully authorizes the MCP server to send Gmail emails
Future
The OAuth 2.1 pieces will soon start to come together in major products that leverage MCP. But today’s MCP authorization model is still rudimentary compared to what we’ve come to expect in mature enterprise platforms – things like fine-grained authorization, step-up authentication, and context-aware access. Companies will expect policy engines to control tool invocation, audit hooks to track unexpected behavior, and access control models that map cleanly onto real world org structures. These will be challenging problems to solve, particularly as existing solutions are not geared toward the nuances of AI interfaces, but solving them is what will be needed to see this technology go beyond local superusers and into the enterprise.
Nice article. Trying to build a hosted MCP that can securely connect to google sheets to make reports. This whole oauth situation is a pain!